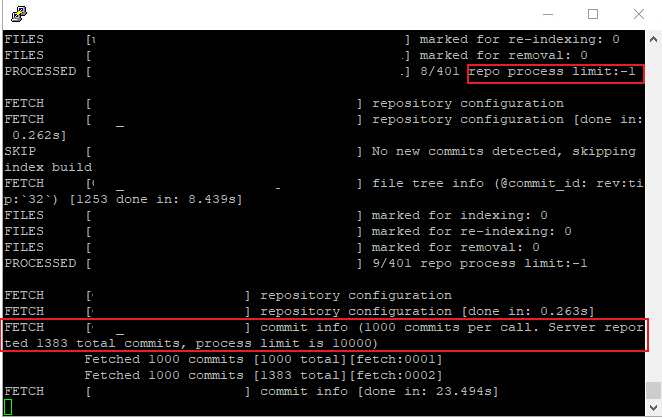
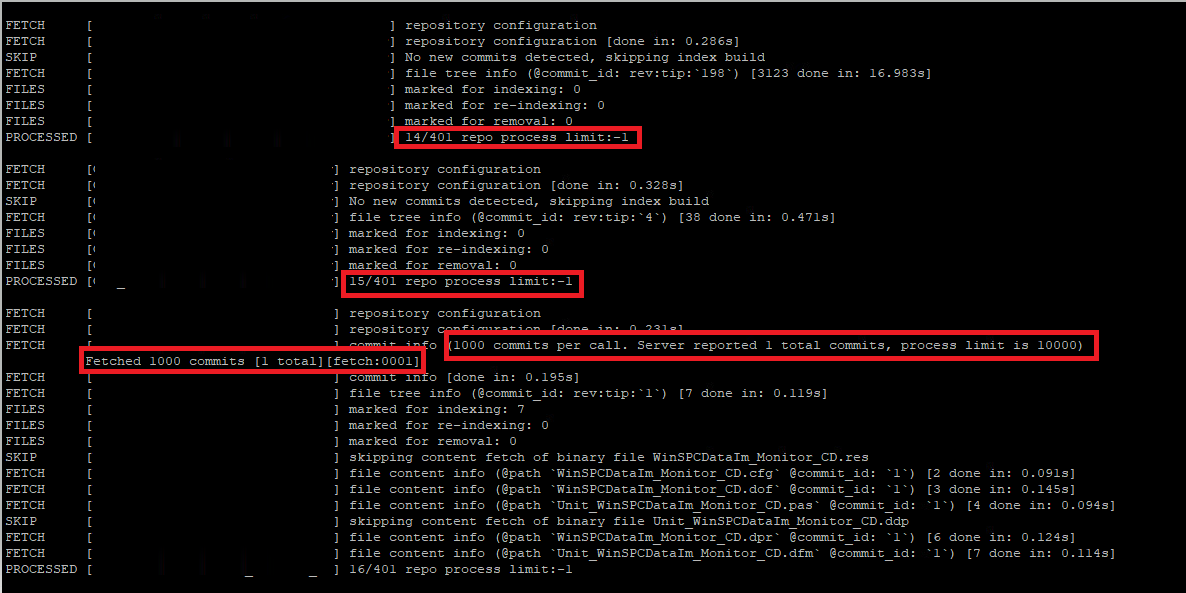
I use the directive rhodecode-index --instance-name=community-1, create Index, Kill will be displayed at the end, and Index cannot be completely created.
What additional information do I need to provide ?
Any ideas what the problem might be?
SYSTEM INFO
CentOS Linux release 8.0.1905 (Core)
RHODECODE CONTROL VERSION: 1.24.4
NAME : community-1
STATUS : RUNNING
logs: /root/.rccontrol/community-1/community.log
I increased the RAM to 16GB and still killed the process halfway through the execution.
Is it because the amount of data is too large?
Or the index can be created in segments.
For example: Create svn Index r01~r1000 this time and r1001~r2000 next time.
I used the parameters --commit fetch limit=100 --commit process_limit=100 --repo limit=1 to successfully set the rhodecode-index, but the scan still does not release the memory.
For example, if I set scan commit_process_limit=100, after version 001~100, the memory will not be released and will continue to accumulate.
I’m truly sorry, but I need to trouble you once more.
Same thing here, I have repos with big files. Even if I skip those with skip_files= and skip_files_content=, the rhodecode-index is still killed prematurely.
Does skip_files really prevent RAM usage? Or is there a way to not kill the process even if out of RAM? (use swap for example)
I personally gave up on indexing file contents (commits only) because of the low amount of RAM on my server. I did this with a command switch instead of the mapping file: